As reported by Tristan Greene on The Next Web, scientists at Kyoto University in Japan have created a deep neural network that can decode brainwaves.
That’s right, AI that can read your mind.
Tristan summarizes:
“When these machines are learning to “read our minds” they’re doing it the exact same way human psychics do: by guessing. If you think of the letter “A” the computer doesn’t actually know what you’re thinking, it just knows what the brainwaves look like when you’re thinking it…. AI is able to do a lot of guessing though — so far the field’s greatest trick has been to give AI the ability to ask and answer its own questions at mind-boggling speed. The machine takes all the information it has — brainwaves in this case — and turns it into an image. It does this over and over until (without seeing the same image as the human, obviously) it can somewhat recreate that image.”
Or, as Guohua Shen, Tomoyasu Horikawa, Kei Majima and Yukiyasu Kamitani illustrate:
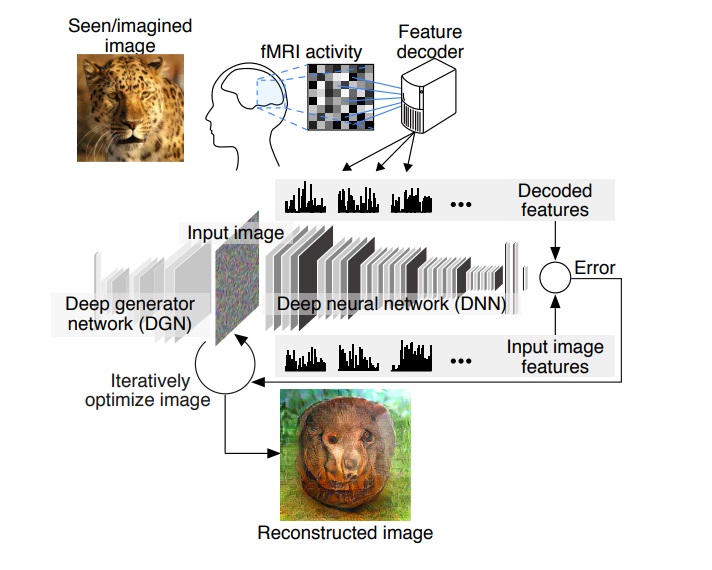
To my eye, some of the results look awfully reminiscent of William Turner‘s oil paintings, particularly Snow Storm.

See the full paper.
My take: Let’s be honest. This technology, as amazing as it is, is not yet ‘magical.’ (Arthur C. Clarke‘s third law is, “Any sufficiently advanced technology is indistinguishable from magic.”) However, if we think about it a bit and mull over the possibilities, this might one day allow you to transcribe your thoughts, paint pictures with your mind or even become telepathic.